
Is the boinc core client and manager going to support IPv6 in the near future?
All of the communication between the core client and project servers is done through a library called libCurl. It has an awesome feature set and it wouldn’t surprise me if they already supported it. A quick pass over their comparison chart says they do. At this point I’m not sure there is anything more we have to do.
Does anybody have some IPv6 gear to test things out on?
Will a future BOINC have an interface tab or an options extension or the like to set any of the ‘override’ parameters?
I’m not sure what you mean by override parameters. If you are referring to the global preferences then yes, the manager will include the ability to override the global preferences. That feature will first make it’s debut with the BSG with a small subset of the overall features, probably within a release after that I’ll add the rest of the global preferences to an enhanced preferences dialog which will be available through the advanced interface.
Currently the simple preferences dialog looks like this:
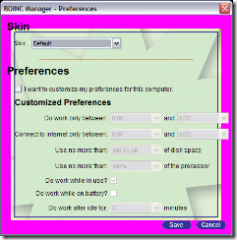
To be fair though, I just got done butchering everything on Friday to take care of a usability issue and WCG hasn’t had a chance to give me an updated bitmap and that is why you can see the magenta border. The general layout is there though, it should look pretty intuitive on how it should work.
Everybody should feel free to provide any first impression feedback, we are all interested in what you all have to say.
any update on new BOINC client interface? can anyone sign up for beta testing?
Well for the last several weeks I’ve been saying we will hit beta this week. So without further ado, we’ll hit beta this week. Kevin and I will probably chat tomorrow and decide what to do. My new target date for a beta release is Wednesday.
Like with all of our beta releases they are available for those who really want to try things out, just be advised that beta releases have bugs and things may not work. In the worst case scenarios’ their could even be data corruption.
When BOINC is updated, it ignores already installed folder; user have to manually choose correct folder – every new BOINC version, every machine running over and over. Any good reason for that?
Nope, none. It is on my plate to fix. I was hoping to have more time in this release to do a couple of things like storing setup information/version upgrade notification, I still might after we get the beta process underway, but right now I’m head down on the Simple GUI until things have stabilized.
So when can those of US who run Windows XP x64 see a Native 64bit Boinc and app?
I suppose when I can get my hands on a 64-bit machine.
I generally buy my own hardware, I have expensive tastes and really don’t like low-budget computer hardware or base configuration models. Down-side to that is I don’t upgrade often, my current workstation I’ve had for several years and probably has another couple of years left on it. Although I have been looking at a few of the dual-processor/dual-core/hyperthread-enabled workstations from Dell. Who knows, I might pick one up next year.
If there is enough demand for a 64-bit build, and for whatever reason Crunch3r and crew are having problems releasing builds, I’m sure David would hook me up with a 64-bit machine.
considering it’s clock-changing weekend: does boinc take into account the fact that the clocks change when recording/calculating processing time?
For the most part BOINC uses Epoch time internally, I suspect BOINC will be superseded by something else before we run into time keeping issues.
why doesn’t boinc use actual CPU time directly?
Any place BOINC can use CPU time to account for the amount of CPU time an application has used, it does. Some operating systems don’t provide a very good way to get at hat information, and in those cases wall clock time is used.
about crashes etc., when something fails/crashes in windows, the user is asked to send a “report” to a Microsoft server somewhere.
Are these reports actually collected from MS for debugging purposes?
Short answer, no, the crashes are uploaded to a Microsoft server, but Microsoft only investigates their own application crashes. Microsoft does offer access to the crash reports to the ‘owners’ of the software so they can download the crash dump files and try to figure out what is going on. You actually shouldn’t be seeing the ‘Error Reporting’ tool which I’ll refer to as Doctor Watson.
BOINC is supposed to be completely autonomous, meaning it just runs in the background and if an application crashes it silently handles it and any diagnostic data that we can get at is analyzed in the background and then uploaded to the project server in a condensed form. I participated in debugging both S@H and R@H applications using this technology and have started to collect and publish little nuggets of information about common crashes. You can find it here:
I’ll continue to add to the list as I find them, or am called in to help isolate bugs in another application. Most of the examples are R@H crash dumps, I should have started the document during the S@H beta cycle, but I didn’t think about it then.
1) the most annoying one is the upload+report & download of new work process with a short cache.
I have a tiny cache (something like 0.0001 days) because i have a premanent Inet connection. When a task is very near finishing, due to my small cache a new workunit is downloaded, and then the near-finishing WU is uploaded and reported. The problem here is that 2 requests are being made, one for new work, then one soon after to report finished work, it would be more sensible to wait for the unit to finish, upload, then report and get new work in one operation, rather than hammer the servers as “return results immediately” does
Will the new CPU scheduler avoid this problem?
John really is the best person to ask about CPU scheduling issues, I’m just a consumer of his and David’s work, same as you.
That said, I do not believe the new CPU scheduler will avoid the problem, one of the goals is to keep the CPU busy, if you finish your result and have to wait for the client to download another one, the CPU isn’t busy.
If I was in your shoes, after the new scheduler is released, I would set my cache size to 1 and let the client re-normalize on that. The days of having a very small cache to keep from missing a deadline should be coming to a close.
4) not a bug, but a question, i’ve got some changes to some of the web code, and i want to checkin my changes to the CVS/SVN system, but obviously i don’t have the permissions to do so. how do i go about getting my changes merged?
Send them to David and/or Rytis and let them look over the changes.
Carl was unable to trap all the exceptions within Visual Studio (unlike the Linux environment which was more helpful) which is why I suggested having a call-back process so that Boinc could get the science app to help with ‘difficult’ exceptions. So you’d still have a black box, just not a cubic one 🙂
Yeah, I’ve been working with AutoDock@Home a little bit trying to help them get setup in there Fortran environment. It appears that the Intel Fortran compiler uses a different form of exceptions than Windows knows about. I found some interoperability documentation between C/C++ and Fortran and suggested some changes. When they let me know how things went we might be able to provide some extra information for those using Fortran in the BOINC environment.
To submit questions for next week just click on the comments link below and submit your question.
Thanks in advance.
—– Rom
References: