First off let me say that Miw is right about the per TCP connection overhead. It applies to file uploads, file downloads, scheduler requests, trickles, forum requests, and now AMS requests.
I also agree with him that if a public facing BOINC project on a single server it would keel-over after an outage because of the file upload requests.
The thing about both the upload and download servers is that their can be any number of them for a project. As a matter of fact all the components except for the scheduler and database can exist on any number of machines. So most of the time we are involved in scale-up vs scale-out debates when brainstorming about future optimizations.
I’ll have to check on the scheduler again to be sure though, as I have a funny feeling I remember some code from Carl C. of CPDN that fiddled around with the feeder query and he may have introduced a way to run multiple schedulers.
The basic gist I want to get across though is that most, if not all, of the components in a BOINC server farm can scale for a project with unlimited funds. Only the database server proves to be difficult to change out as S@H experienced during their database server upgrade. In BOINC’s defense on that issue, I would like to point out that the database file formats changed when switching from Solaris to Linux, so the database had to be dumped to a flat file and reloaded on the new machine.
I believe that the file upload and download servers are used as dams most of the time to keep the rest of the system from keeling over, for instance if the those servers were not keeping the hoards of machines at bay and everything was gated on the database then after an outage nobody would be able to use the website, or read/post in the forums.
By far the easiest servers to replace in a BOINC server farm are the upload/download servers, all you need is a Linux box and Apache. File uploads are handled with a small CGI program.
I’ll talk to David tomorrow and see if accepting 2 or 3 files during an upload request makes since, it sounds good on the surface but I’m concerned about the increased disk bandwidth requirements. S@H for instance has a shared disk array for file uploads and downloads, when that array is bogged down then the whole pipeline boggs down.
So all-in-all I’m really impressed with wxWidgets. Most of the time it is pretty straight forward and easy to figure out, but on Wednesday night through Thursday I was frustrated with the framework. The documentation made it sound easy, and in the end it was easy, but getting their wasn’t so easy.
I went through about 15 iterations before finding the right solution. My worst solution took 2 minutes to finish a re-paint, but it finally did paint everything the right way. During the 2 minutes though there was enough flicker it might have sent somebody into convulsions. I even attempted to use Google to see what others had done, most of the references were really old and stale, all of them didn’t seem to work anymore with 2.6. So I’m posting my solution for others to find and use.
Is the boinc core client and manager going to support IPv6 in the near future?
All of the communication between the core client and project servers is done through a library called libCurl. It has an awesome feature set and it wouldn’t surprise me if they already supported it. A quick pass over their comparison chart says they do. At this point I’m not sure there is anything more we have to do.
Does anybody have some IPv6 gear to test things out on?
Will a future BOINC have an interface tab or an options extension or the like to set any of the ‘override’ parameters?
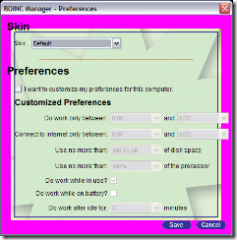
I’m not sure what you mean by override parameters. If you are referring to the global preferences then yes, the manager will include the ability to override the global preferences. That feature will first make it’s debut with the BSG with a small subset of the overall features, probably within a release after that I’ll add the rest of the global preferences to an enhanced preferences dialog which will be available through the advanced interface.
Currently the simple preferences dialog looks like this:
To be fair though, I just got done butchering everything on Friday to take care of a usability issue and WCG hasn’t had a chance to give me an updated bitmap and that is why you can see the magenta border. The general layout is there though, it should look pretty intuitive on how it should work.
Everybody should feel free to provide any first impression feedback, we are all interested in what you all have to say.
any update on new BOINC client interface? can anyone sign up for beta testing?
Well for the last several weeks I’ve been saying we will hit beta this week. So without further ado, we’ll hit beta this week. Kevin and I will probably chat tomorrow and decide what to do. My new target date for a beta release is Wednesday.
Like with all of our beta releases they are available for those who really want to try things out, just be advised that beta releases have bugs and things may not work. In the worst case scenarios’ their could even be data corruption.
When BOINC is updated, it ignores already installed folder; user have to manually choose correct folder – every new BOINC version, every machine running over and over. Any good reason for that?
Nope, none. It is on my plate to fix. I was hoping to have more time in this release to do a couple of things like storing setup information/version upgrade notification, I still might after we get the beta process underway, but right now I’m head down on the Simple GUI until things have stabilized.
So when can those of US who run Windows XP x64 see a Native 64bit Boinc and app?
I suppose when I can get my hands on a 64-bit machine.
I generally buy my own hardware, I have expensive tastes and really don’t like low-budget computer hardware or base configuration models. Down-side to that is I don’t upgrade often, my current workstation I’ve had for several years and probably has another couple of years left on it. Although I have been looking at a few of the dual-processor/dual-core/hyperthread-enabled workstations from Dell. Who knows, I might pick one up next year.
If there is enough demand for a 64-bit build, and for whatever reason Crunch3r and crew are having problems releasing builds, I’m sure David would hook me up with a 64-bit machine.
considering it’s clock-changing weekend: does boinc take into account the fact that the clocks change when recording/calculating processing time?
For the most part BOINC uses Epoch time internally, I suspect BOINC will be superseded by something else before we run into time keeping issues.
why doesn’t boinc use actual CPU time directly?
Any place BOINC can use CPU time to account for the amount of CPU time an application has used, it does. Some operating systems don’t provide a very good way to get at hat information, and in those cases wall clock time is used.
about crashes etc., when something fails/crashes in windows, the user is asked to send a “report” to a Microsoft server somewhere. Are these reports actually collected from MS for debugging purposes?
Short answer, no, the crashes are uploaded to a Microsoft server, but Microsoft only investigates their own application crashes. Microsoft does offer access to the crash reports to the ‘owners’ of the software so they can download the crash dump files and try to figure out what is going on. You actually shouldn’t be seeing the ‘Error Reporting’ tool which I’ll refer to as Doctor Watson.
BOINC is supposed to be completely autonomous, meaning it just runs in the background and if an application crashes it silently handles it and any diagnostic data that we can get at is analyzed in the background and then uploaded to the project server in a condensed form. I participated in debugging both S@H and R@H applications using this technology and have started to collect and publish little nuggets of information about common crashes. You can find it here:
http://boinc.berkeley.edu/app_debug_win.php
I’ll continue to add to the list as I find them, or am called in to help isolate bugs in another application. Most of the examples are R@H crash dumps, I should have started the document during the S@H beta cycle, but I didn’t think about it then.
1) the most annoying one is the upload+report & download of new work process with a short cache. I have a tiny cache (something like 0.0001 days) because i have a premanent Inet connection. When a task is very near finishing, due to my small cache a new workunit is downloaded, and then the near-finishing WU is uploaded and reported. The problem here is that 2 requests are being made, one for new work, then one soon after to report finished work, it would be more sensible to wait for the unit to finish, upload, then report and get new work in one operation, rather than hammer the servers as “return results immediately” does Will the new CPU scheduler avoid this problem?
John really is the best person to ask about CPU scheduling issues, I’m just a consumer of his and David’s work, same as you.
That said, I do not believe the new CPU scheduler will avoid the problem, one of the goals is to keep the CPU busy, if you finish your result and have to wait for the client to download another one, the CPU isn’t busy.
If I was in your shoes, after the new scheduler is released, I would set my cache size to 1 and let the client re-normalize on that. The days of having a very small cache to keep from missing a deadline should be coming to a close.
4) not a bug, but a question, i’ve got some changes to some of the web code, and i want to checkin my changes to the CVS/SVN system, but obviously i don’t have the permissions to do so. how do i go about getting my changes merged?
Send them to David and/or Rytis and let them look over the changes.
Carl was unable to trap all the exceptions within Visual Studio (unlike the Linux environment which was more helpful) which is why I suggested having a call-back process so that Boinc could get the science app to help with ‘difficult’ exceptions. So you’d still have a black box, just not a cubic one 🙂
Yeah, I’ve been working with AutoDock@Home a little bit trying to help them get setup in there Fortran environment. It appears that the Intel Fortran compiler uses a different form of exceptions than Windows knows about. I found some interoperability documentation between C/C++ and Fortran and suggested some changes. When they let me know how things went we might be able to provide some extra information for those using Fortran in the BOINC environment.
To submit questions for next week just click on the comments link below and submit your question.
Significant amount of time and energy has gone into making BOINC’s communication infrastructure efficient, yet there are still many whom believe that it really doesn’t cost the projects any more to return the results immediately vs. returning the results when BOINC believes it ought too.
For the purposes of this article I’m going to define the cost of a query at $1.00 per query to cover the cost of electricity, air conditioning, maintenance, and cost of personal to manage the database server. Now in real life that number is greatly exaggerated, but it is easier to describe the relative cost of something based off of something tangible.
Here is a basic rundown of query cost per MySQL documentation:
Selects happen really fast since that is what databases are optimized around
Updates are only a little more expensive than a select because they have to acquire an exclusive lock on the row to make sure nobody else is trying to write to that record and then change the record.
Now with using FastCGI we can throw out the connecting and closing costs since the database connection is always available for the life of a single scheduler process, which their can be 100-150 running at a time.
We’ll keep track of the number of queries executed and the number of query parts used so we can calculate the cost per query part.
Well break out the results for the following two scenarios:
Reporting 20 results individually.
Reporting 20 results at once.
Scheduler RPC
A scheduler RPC does many things as it has to do authentication, preferences, receive incoming result status, and send out new results to be processed. I’ll tackle each section one at a time.
Authentication
Authentication consists of a query for host, user, and team. Each query is independent, although we have talked about batching them into a single query, we just haven’t gotten that far yet. Now this part of the RPC may result in a new host record being created if your connecting up for the first time or something is wrong with what you have sent to the scheduler.
Scenario 1: 60 Queries, 360.6 Query parts.
Scenario 2: 3 Queries, 18.03 Query parts.
Platform Check
Checks to see if your platform is supported.
Scenario 1: 20 Queries, 120.2 Query parts.
Scenario 2: 1 Queries, 6.01 Query parts.
Preferences Check
Determines if the preferences on the client need to be updates or the server needs to be updated. If the server needs to be updated then an update query is submitted.
Scenario 1: 20 Queries, 120.2 Query parts.
Scenario 2: 1 Queries, 6.01 Query parts.
Handle Reported Results
Here each result is looked up to see if it was assigned to the person reporting it and to update its values. The workunit record for each result record has to be updated so the transitioner will look at the workunit and decide what to do next. Two indexes have to be updated in the result table and 1 in the workunit table for each result. What is important to point out here is that in scenario 2 we batch all of the selects and updates for results in scenario 1 into a single select and update. The workunit updates are also batched in scenario 2.
Scenario 1: 60 Queries, 342.2 Query parts.
Scenario 2: 3 Queries, 17.11 Query parts.
Assign New Results
Most of the preparation work for this phase is actually done by the feeder. So here we get the latest information about the result, then update the result, then update the workunit.
Scenario 1: 60 Queries, 342.2 Query parts.
Scenario 2: 60 Queries, 342.2 Query parts.
Totals
Now that we have broken down the scheduler into each of its parts and isolated the number and types of queries we can calculate what it would cost the project if each query cost $1. The query parts metric is useful in determining how much wasted database time is spent for each operation. All around scenario 2 costs the project less in time and maintenance on equipment.
Scenario 1 costs a project $11 per result, and scenario 2 costs a project $3.40 per result.
Scenario 2 is 70% more efficient than scenario 1 in the amount of time used to process 20 results.
So be kind to your project(s), let BOINC report the results in batches. The project admin’s will be able to support more people and more machines with the same hardware.
—– Rom
[Edit: Since originally writing this I hunted down a few numbers from jocelyn which is the S@H database server
On average jocelyn is processing 314 queries per second. In the last 5 days jocelyn has processed 144.7 million queries.
Can we get more (unlimited – well, within reason!) preferences than home, school and work? Three profiles isn’t enough for me and I’m only running a small number of computers. I know these can be overridden (although the project preferences for Rosetta (i.e. runtimes) cannot)I’d find it really useful if these profiles could be added to as required, and please can you make them renamable?!?
I believe the account manager folks are working on some features which will allow greater configuration flexibility. The BOINC client is capable of dealing with a greater number of zones, there just hasn’t been an easy way of configuring them on a project’s web site. Rytis is now at the helm of the project web site and forum features. I’m looking forward at seeing what he is going to cook up.
Also, any update on BOINC on the consoles?
Well there is a lot of buzz, but nobody has signed on the dotted lines yet. David and Eric are going to a Sony R&D center next week to meet some engineers for the PS3. I haven’t heard anything new about the XBOX 360, the XNA Game Studio from Microsoft is a bust for BOINC, it assumes all of the game code is going to be managed code on the 360. So that leaves us with the need of the same development kit as the professional game studios use.
Again moor of a request i am attached to a lot of projects and when I need to take a box out of service(without throwing away wu) I have to click “no new tasks” over 30 times. A bit tedious especially over VNC. A global (per host)no new tasks button would be of great use to me.
Is the global update ever returning? Although I can see where it can be abused.
Right now many things are on hold until after we can get the BSG out the door. Tentatively I have some time allocated to re-work the Advanced UI and playing around with Vista has inspired me on how to handle the multi-selection cases in a list view control. We shall see though.
‘Retry Communications’ is about as close as your going to get for an update all type function. It basically resets the countdown timer for any pending action.
With regards to the whole ‘-return_results_immediately’ thing, from a project perspective it is altogether evil. I’ll write up another post about that separately.
1) What are the typical things which cause the work unit to fail? (Environmental – antivirus, graphics drivers, excessive overclocking, PC crashes, playing games for hours, video encoding, etc. Human factors – Misunderstanding boinc messages, for example incorrect URL – they detach and attach, then get upset that x months of work is ‘down the pan’. Ditto installation of berkeley version over bbc version, easy to fix but they don’t know how)
You have nailed the majority of cases. I mean we could go off into the really obscure cases like cosmic rays and the like, but you covered all the things in the majority case.
In the future we won’t be allowing a directory name change for any software package that we build for others, so that should take care of any potential future BBC issues. Now before you all think I’m making up the whole cosmic ray thing here is an article from ZDNet about eBay suffering one to two crashes a month due to a defect in their ECC memory which left them prone to cosmic rays.
2) Is there anything which can be done to avoid these, either by the science app or by Boinc itself? (Uploading partial results as the WU runs. Exception handlers, both at science app and callbacks at boinc? Restart from checkpoint/backup if error code 0,-107…,etc etc received? Going into hibernation if PC is very busy, out of memory, etc)
This is one of those really cool but really though questions. Each environment handles things a bit differently. About the best advice I can give is for each project to really understand how the programming language they are using interacts with the operating system they are using.
CPDN is advancing the trickle model to the point where they could resend out a workunit that has timed out and take the previous users trickles and reuse them as the starting point of the new work unit.
One thing I would like to point out is that BOINC itself cannot do anything about a science application failure except fail the workunit and move on to the next one. To BOINC each of the science applications are a little black box and the only way BOINC knows anything about what is going on inside is through a little 8k chunk of shared memory broken up into 8 channels. Simple commands are passed around in these channels like show graphics, hide graphics, and here is the amount of CPU time I’ve used.
Now exceptions, and error tracking in general, use pointers in the local address space for the science application. For BOINC to be able to track exceptions in a science application would mean that BOINC would have to act like a debugger while the science application is running which would cause a 20-30% performance decrease for all science applications, and would more than likely negate any optimizations available to an application.
We did add a little something to the BOINC API library which we internally refer to the ‘BOINC runtime debugger’. This little chunk of code is compiled into the science application and informs the OS that if any unhandled exceptions happen, it needs to execute a chunk of code. Using stackwalker as a template we expanded the functionality and improved the data returned to the project using a Microsoft library on Windows to dump out as much information about the exception as possible. This code isn’t ever executed or used unless an unhandled exception happens within an application, so no performance decrease is experienced.
I’m going to need to write a whole different article on this topic.
3) What support does Boinc have / plan to have which relate to this category of work unit specifically? (e.g.) some ideas, many of which may be impractical – * Separation of graphics from the work unit so that a temporary problem with the graphics drivers doesn’t cause the WU to fail
Separation of the graphics code from the worker code will probably start at the beginning of next year. It is going to be a requirement for supporting Vista and other OS’s as they increase in their defense in depth models.
* Automatic backups * Backups which are per-workunit rather than for all workunits which happen to be running
There are other tools that can be used for backups. Frankly, trying to tackle that role is complicated and really outside the design scope for BOINC.
* Callbacks from Boinc into science app to allow the science app to handle boinc exceptions it wouldn’t normally be able to trap
What kind of exceptions do you think the science applications need to handle?
* Handling of the situation where the PC is very busy, out of memory or other resources, about to crash, TCP/IP stack blocked…)
We are adding more smarts into the CPU scheduler to handle the memory/paging cases.
Crashing is a random event, the only way you could know something is about to crash would be to already know what the bug is.
We added some code awhile back to test the various communication mechanisms when BOINC is first launched, that should have taken care of the TCP/IP blocks. If you know of any cases we haven’t covered with recent builds let me know.
how’s the progress with allowing AMS/BMS/BAM (whatever it’s called these days) to control the state of projects and WUs such as setting NNW, or suspending a project/task?
I believe this code is in for the 5.8.x release.
Farm Managers ? Farm Manager ability came with Account Managers, I cannot find any programs on the BOINC website to install a Farm Manager on my computer, what is it? is it working? or has it been abandoned?
A farm manager is an idea that James Drews had, I believe, that is geared towards managing hundreds of machines. Basically you setup a web server which acts as a private AMS, the BOINC client includes it’s IP address, port number, and GUI RPC password (I think) when it first connects to the farm manager. After that if you want to do something specific to a machine the farm manager can issue a GUI RPC just like the BOINC Manager. I’m not sure if anybody besides James has done anything about creating a farm manager package.
BOINCView is probably the best bet unless you come by several hundred machines.
Auto update of ‘BOINC’ ?
Funny you should ask this, WCG was asking about this very same thing. We’ll probably start looking into something like this for the 5.10 release.
We were always concerned if we had put something like that in place it might be exploited by an attack vector we never even thought of. At least with a human at the other end of the equation the amount of damage would be limited.
Now with WCG as a contributor we can get the IBM security department to look things over and let us know if something is really wrong. IBM has looked over the BOINC source once already so we are confident we have our i’s dotted and our t’s crossed but with auto-deployment of code without user intervention you can never be too careful.
I am new to BOINC and I’m loving it, but I was wondering: are any plans for BOINC to use the powerful new age GPU’s and PhysX processors that are perfect for floating point computations?
FluffyChicken Wrote:
I can answer the last one, ATI(AMD) have asked BOINC if they would like help, though it would be the projects that would need the help if the GPU is capable. NVIDIA would probably need to jump in if your(we) are going to get it running on that, or somebody like Microsoft developes an easy to use API (Accelerator in research ?) As for PhysX, we (some members in the forum) contacted them from Rosetta@home and had no real rosponse. Rosetta@Home are in talks with Microsoft for the XBOX360 though, apparently.
I would just like to add that with the next release BOINC currently detects your video card and processor capabilities and reports them to the project. If/when a project commits to using a graphics card or physics accelerator we could go through with the rest of the work items to turn them into a resource that can be scheduled for use.
We added in the detection code so we could try and get the stats sites to break down video card usage and processor capabilities, maybe spur on the projects to develop specific customized applications to harness the untapped capabilities of the machines.
It is much easier to go to a project and sell them with hard numbers than to say we think this could help you by ‘x’ amount.
To submit questions for next week just click on the comments link below and submit your question.
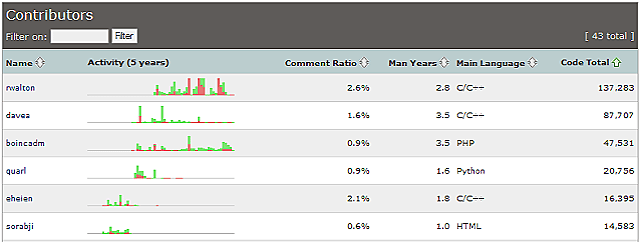
It generates many charts and graphics about the changes it detects in the source tree over time. I have looked over quite a few things and got to heckle David a bit about some of the graphs. I really got a kick out of this chart:
To be fair though I need to point out that David checks in code using ‘davea’, ‘boincadm’, and ‘sorabji’ depending on where or when he has checked in code.
So I spent some time this weekend tweaking my blogs look and feel. Saturday afternoon I just got a burr up my butt and decided to do something about it.
I took some of his advice and made the following changes:
Added a profile
Moved my contact info and email signing certificate to the header
Optimized the viewing space for 1024×768
I went so far as to include links to translate my postings to Spanish, German, French, Portuguese, Japanese, Chinese, and Arabic.
I’ve contacted the Feedburner crew about fixing the link text for the actual links within the RSS feed itself. For some reason the encoding’s get borked.
Hopefully the translations Google does for me won’t offend anybody. 🙂
Advanced Memory Management, what is the idea/aim behind that?
Well that is a good question, the advanced memory management is more about setting boundary conditions on how much BOINC and related processes are allowed to use.
We still get a few reports of BOINC causing systems to become unresponsive or sluggish. Most of the investigations we have done revealed a machine that was paging a lot during the times BOINC was running. Paging is the process the OS uses to free up less frequently used memory to make room for active tasks by writing those pages of memory to disk. Each page of memory is roughly 4KB in size on a x86 processor.
So lets say you are running a machine with 512MB’s of memory. Windows XP uses roughly 128MB of that on boot-up and will allow parts of itself to be paged out to disk. The last round of virus scanners I looked at want around 100MB of memory, the little system tray icons in the lower right part of your screen generally take about 5MB a piece, with the notable exception of the various IM clients which have bloated out to 20-60MB a piece. Any additional programs running on your machine such as a web browser or email client can take anywhere from 20MB up to 100MB.
When the OS comes under memory pressure it starts looking for chunks of memory that haven’t been touched in awhile and writes them out to disk and then loads something into that chunk of memory that is more relevant.
So let us say that you are attached to R@H and you walk away from your computer for an hour or so, during that time R@H has used over 256MBs of memory continuously for at least 30 minutes and the OS has had to page a lot of stuff to make room for it, including itself. You start menu has to be reread from disk or whichever application you happen to be using before you left. All of that paging takes a few moments and makes your computer feel really really slow.
With the introduction of this feature we hope we can finally close one of the last remaining loopholes to user responsiveness.
Right now we have the following two settings planned:
Percentage of memory use while user is active.
Percentage of memory use while user is idle.
What should happen is that BOINC will detect how much memory is installed on the machine, and every 10 seconds or so looks at how much memory a science application is using. If a science application exceeds the total allotment BOINC will shut it down and look for another application to schedule.
I’m really looking forward to this feature since my 2GB machine uses about 1.2GB of memory without BOINC even running and I have four processors to feed. Up until the middle of last year I only had 1GB in my machine and if I had BOINC running it was pretty painful when BOINC rescheduled all the science applications on the machine while I was working.
Scheduler Improvents (already implemented?) how do these help ?
As far as I know John Mcleod has finished the work on the new scheduler and work-fetch policy. The new system should reduce the number of wasted cycles lost between the last checkpoint for an application and when it needed to quite due to a reschedule to honor resource shares.
John is really the wizard in this area.
How are any other improvement going to improve us? and the projects?
I believe the two major work items over the next year will probably be the inclusion of the projects to be able to use torrents in their file download process and the ability for projects to be able to send out optimized science applications for each processor type and possibly GPU enabled applications.
Is there anybody working on boinczilla? Bug reports are raising and nobody sort it out :/
My bad, I’ll see what I can do about that this weekend.
Why not run the benchmark at higher priority, so each system produces a constant value, rather than the haphazard, particular as occurring only every 5 days?
The idea behind running the benchmarks at the same priority level as the science applications is to get a rough idea how how many cycles the science applications will get. If you run the benchmarks at a normal thread priority it won’t be that much more consistent, and if you run them at the highest thread priority a user mode application can have you’ll get numbers that are not very realistic for a science application running as an idle process.
The systems are benchmarked every 5 days or so to handle changes to the environment, such as a more resource intensive virus scanner or any content indexing systems that might have been installed.
When are we going to see the first alpha/beta with the BSG?
Hopefully next week.
With regard to the idea of switching tasks at a checkpoint, what happens (as in, are there any checks etc) when an application gets “stuck” and doesn’t make any progress? This also applies to a similar situation with current apps, where they get stuck and the clint tries and tries to get it done by the aproching deadline, but obviously never will. This pushes the client into NNW and EDF. Will BOINC abandon the unit if no progress is made, or the deadline is met?
To be honest, I don’t know. I’ll have to bug John and David about that.
Is there any possibilty of releasing 5.6.4 or 5.6.5 as alternate versions?
I don’t intend to put them on the download page. But if you feel comfortable with the quality of the client that you feel you can recommend people to use it, then go ahead and give them the link. I think we were far enough along in the testing process to know it isn’t going to cause any major problems and might have only a few small bugs left before it was ready to be released.
The reason for not adding it to the download page is then people would receive a message in the message long requesting they upgrade to it. If all goes according to plan we’ll be able to release 5.8 in a few weeks, and it would be a bad experience to bug people about upgrading twice in one month.
I suspect that if somebody was experiencing a bug that is fixed in 5.6 they would be happy to start using it now and not be so annoyed when they see the upgrade notice for 5.8.
Is there any chance of a purge function being implemented?
I haven’t heard any talk of one. I’ll bring it up with David, it sounds like something a project might want.
Hot topic: Why is the hourly benchmark value between Linux and Windows different, or it’s claimed. When done with stock BOINC 5.4.9 e.g. on Windows it kicks out 8.1 per hour, when same done under Linux, it kicks out 5.0. The WU’s are processed at equal speed i.e. a job on Wondows taking 2 CPU hours would take near equal time on Linux.
It has been my experience that the Microsoft compiler has been better at optimization than the GCC compiler. I’m sure I’ll get flamed by the OSS crowd but most of the projects are experiencing the same result.
I should point out that the optimizers have been able to equal things out by a lot of trial and error by turning off and on the various optimization switches for GCC.
If the optimizers want to submit a patch that contains different non-CPU specific optimizations I’m sure we could use them.
To submit questions for next week just click on the comments link below and submit your question.
Thanks in advance.
—– Rom
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
FunctionalAlways active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.