During the install of BOINC as a Windows service, you are required to enter an account which will be used to launch the BOINC service. Why do you need this? I can manually convert the service over to “Local System” without requiring credentials at all and it still seems to work OK.
“LocalSystem” is a special account, it has more permissions on the system then even the administrator account.
My goal in setting up the installer that way was to try and get people to be a little more paranoid about which account they were going to use as the service account.
For instance if you use your computer to track your finances you probably don’t want to be running BOINC using the LocalSystem account. Even if you initially removed permissions from your financial records for the LocalSystem account any process running under that account can take ownership of those files and read them anyway.
We actually talked about the whole trust thing at the conference, how do we as a community know if a new project is trust worthy? How do we know their application is doing what it claims to be doing?
As an off shoot of that conversation, how do we minimize the damages a potential project can cause on a computer system? The most obvious answer is don’t run as LocalSystem/Administrator/root.
The safest way to run BOINC as a service is to create a limited user account just for the BOINC service.
What about PNG alpha channel on skin elements? For example, transparent elements on the “workunit background” should let the main GUI background seen through.
We need to investigate what is going on their. I’ll let you all know as soon as we find something out.
I would like to modify an existing manager skin like the wcg. I would only like to change some of the background graphics to brand for my BOINC team “Team ACC – Arthur C Clarke” I don’t want to change any of the buttons, tabs, etc. How can I get a complete skin including the graphic files? With that I could replace only the couple of pieces I need.
This actually turns out to be easier than it sounds.
First off the skin manager attempts to load whatever was defined in the skin.xml file, if it can’t find the file it defaults to the BOINC default image for whatever it was looking for. So that means for your skin.xml file all you would need to define is the background image tag like so:
graphic/simplegui_bg.png 133:181:178
So you could have a directory layout that looked like this:
JM7 posted a nugget of information I missed about how DCF is used in this S@H post.
Actually, ROM missed a little. A score less than 1 means that your computer finishes work faster than expected for its benchmarks. A score that is higher indicates that it finishes slower than expected for its benchmarks. It is calculated as a safety for the CPU scheduler (finish on time) and work fetch (not too much), therefore under estimates are corrected very quickly (single step) and over estimates are corrected much more cautiously.
First off let me say that Miw is right about the per TCP connection overhead. It applies to file uploads, file downloads, scheduler requests, trickles, forum requests, and now AMS requests.
I also agree with him that if a public facing BOINC project on a single server it would keel-over after an outage because of the file upload requests.
The thing about both the upload and download servers is that their can be any number of them for a project. As a matter of fact all the components except for the scheduler and database can exist on any number of machines. So most of the time we are involved in scale-up vs scale-out debates when brainstorming about future optimizations.
I’ll have to check on the scheduler again to be sure though, as I have a funny feeling I remember some code from Carl C. of CPDN that fiddled around with the feeder query and he may have introduced a way to run multiple schedulers.
The basic gist I want to get across though is that most, if not all, of the components in a BOINC server farm can scale for a project with unlimited funds. Only the database server proves to be difficult to change out as S@H experienced during their database server upgrade. In BOINC’s defense on that issue, I would like to point out that the database file formats changed when switching from Solaris to Linux, so the database had to be dumped to a flat file and reloaded on the new machine.
I believe that the file upload and download servers are used as dams most of the time to keep the rest of the system from keeling over, for instance if the those servers were not keeping the hoards of machines at bay and everything was gated on the database then after an outage nobody would be able to use the website, or read/post in the forums.
By far the easiest servers to replace in a BOINC server farm are the upload/download servers, all you need is a Linux box and Apache. File uploads are handled with a small CGI program.
I’ll talk to David tomorrow and see if accepting 2 or 3 files during an upload request makes since, it sounds good on the surface but I’m concerned about the increased disk bandwidth requirements. S@H for instance has a shared disk array for file uploads and downloads, when that array is bogged down then the whole pipeline boggs down.
Is the boinc core client and manager going to support IPv6 in the near future?
All of the communication between the core client and project servers is done through a library called libCurl. It has an awesome feature set and it wouldn’t surprise me if they already supported it. A quick pass over their comparison chart says they do. At this point I’m not sure there is anything more we have to do.
Does anybody have some IPv6 gear to test things out on?
Will a future BOINC have an interface tab or an options extension or the like to set any of the ‘override’ parameters?
I’m not sure what you mean by override parameters. If you are referring to the global preferences then yes, the manager will include the ability to override the global preferences. That feature will first make it’s debut with the BSG with a small subset of the overall features, probably within a release after that I’ll add the rest of the global preferences to an enhanced preferences dialog which will be available through the advanced interface.
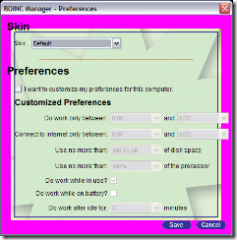
Currently the simple preferences dialog looks like this:
To be fair though, I just got done butchering everything on Friday to take care of a usability issue and WCG hasn’t had a chance to give me an updated bitmap and that is why you can see the magenta border. The general layout is there though, it should look pretty intuitive on how it should work.
Everybody should feel free to provide any first impression feedback, we are all interested in what you all have to say.
any update on new BOINC client interface? can anyone sign up for beta testing?
Well for the last several weeks I’ve been saying we will hit beta this week. So without further ado, we’ll hit beta this week. Kevin and I will probably chat tomorrow and decide what to do. My new target date for a beta release is Wednesday.
Like with all of our beta releases they are available for those who really want to try things out, just be advised that beta releases have bugs and things may not work. In the worst case scenarios’ their could even be data corruption.
When BOINC is updated, it ignores already installed folder; user have to manually choose correct folder – every new BOINC version, every machine running over and over. Any good reason for that?
Nope, none. It is on my plate to fix. I was hoping to have more time in this release to do a couple of things like storing setup information/version upgrade notification, I still might after we get the beta process underway, but right now I’m head down on the Simple GUI until things have stabilized.
So when can those of US who run Windows XP x64 see a Native 64bit Boinc and app?
I suppose when I can get my hands on a 64-bit machine.
I generally buy my own hardware, I have expensive tastes and really don’t like low-budget computer hardware or base configuration models. Down-side to that is I don’t upgrade often, my current workstation I’ve had for several years and probably has another couple of years left on it. Although I have been looking at a few of the dual-processor/dual-core/hyperthread-enabled workstations from Dell. Who knows, I might pick one up next year.
If there is enough demand for a 64-bit build, and for whatever reason Crunch3r and crew are having problems releasing builds, I’m sure David would hook me up with a 64-bit machine.
considering it’s clock-changing weekend: does boinc take into account the fact that the clocks change when recording/calculating processing time?
For the most part BOINC uses Epoch time internally, I suspect BOINC will be superseded by something else before we run into time keeping issues.
why doesn’t boinc use actual CPU time directly?
Any place BOINC can use CPU time to account for the amount of CPU time an application has used, it does. Some operating systems don’t provide a very good way to get at hat information, and in those cases wall clock time is used.
about crashes etc., when something fails/crashes in windows, the user is asked to send a “report” to a Microsoft server somewhere. Are these reports actually collected from MS for debugging purposes?
Short answer, no, the crashes are uploaded to a Microsoft server, but Microsoft only investigates their own application crashes. Microsoft does offer access to the crash reports to the ‘owners’ of the software so they can download the crash dump files and try to figure out what is going on. You actually shouldn’t be seeing the ‘Error Reporting’ tool which I’ll refer to as Doctor Watson.
BOINC is supposed to be completely autonomous, meaning it just runs in the background and if an application crashes it silently handles it and any diagnostic data that we can get at is analyzed in the background and then uploaded to the project server in a condensed form. I participated in debugging both S@H and R@H applications using this technology and have started to collect and publish little nuggets of information about common crashes. You can find it here:
http://boinc.berkeley.edu/app_debug_win.php
I’ll continue to add to the list as I find them, or am called in to help isolate bugs in another application. Most of the examples are R@H crash dumps, I should have started the document during the S@H beta cycle, but I didn’t think about it then.
1) the most annoying one is the upload+report & download of new work process with a short cache. I have a tiny cache (something like 0.0001 days) because i have a premanent Inet connection. When a task is very near finishing, due to my small cache a new workunit is downloaded, and then the near-finishing WU is uploaded and reported. The problem here is that 2 requests are being made, one for new work, then one soon after to report finished work, it would be more sensible to wait for the unit to finish, upload, then report and get new work in one operation, rather than hammer the servers as “return results immediately” does Will the new CPU scheduler avoid this problem?
John really is the best person to ask about CPU scheduling issues, I’m just a consumer of his and David’s work, same as you.
That said, I do not believe the new CPU scheduler will avoid the problem, one of the goals is to keep the CPU busy, if you finish your result and have to wait for the client to download another one, the CPU isn’t busy.
If I was in your shoes, after the new scheduler is released, I would set my cache size to 1 and let the client re-normalize on that. The days of having a very small cache to keep from missing a deadline should be coming to a close.
4) not a bug, but a question, i’ve got some changes to some of the web code, and i want to checkin my changes to the CVS/SVN system, but obviously i don’t have the permissions to do so. how do i go about getting my changes merged?
Send them to David and/or Rytis and let them look over the changes.
Carl was unable to trap all the exceptions within Visual Studio (unlike the Linux environment which was more helpful) which is why I suggested having a call-back process so that Boinc could get the science app to help with ‘difficult’ exceptions. So you’d still have a black box, just not a cubic one 🙂
Yeah, I’ve been working with AutoDock@Home a little bit trying to help them get setup in there Fortran environment. It appears that the Intel Fortran compiler uses a different form of exceptions than Windows knows about. I found some interoperability documentation between C/C++ and Fortran and suggested some changes. When they let me know how things went we might be able to provide some extra information for those using Fortran in the BOINC environment.
To submit questions for next week just click on the comments link below and submit your question.
Significant amount of time and energy has gone into making BOINC’s communication infrastructure efficient, yet there are still many whom believe that it really doesn’t cost the projects any more to return the results immediately vs. returning the results when BOINC believes it ought too.
For the purposes of this article I’m going to define the cost of a query at $1.00 per query to cover the cost of electricity, air conditioning, maintenance, and cost of personal to manage the database server. Now in real life that number is greatly exaggerated, but it is easier to describe the relative cost of something based off of something tangible.
Here is a basic rundown of query cost per MySQL documentation:
Selects happen really fast since that is what databases are optimized around
Updates are only a little more expensive than a select because they have to acquire an exclusive lock on the row to make sure nobody else is trying to write to that record and then change the record.
Now with using FastCGI we can throw out the connecting and closing costs since the database connection is always available for the life of a single scheduler process, which their can be 100-150 running at a time.
We’ll keep track of the number of queries executed and the number of query parts used so we can calculate the cost per query part.
Well break out the results for the following two scenarios:
Reporting 20 results individually.
Reporting 20 results at once.
Scheduler RPC
A scheduler RPC does many things as it has to do authentication, preferences, receive incoming result status, and send out new results to be processed. I’ll tackle each section one at a time.
Authentication
Authentication consists of a query for host, user, and team. Each query is independent, although we have talked about batching them into a single query, we just haven’t gotten that far yet. Now this part of the RPC may result in a new host record being created if your connecting up for the first time or something is wrong with what you have sent to the scheduler.
Scenario 1: 60 Queries, 360.6 Query parts.
Scenario 2: 3 Queries, 18.03 Query parts.
Platform Check
Checks to see if your platform is supported.
Scenario 1: 20 Queries, 120.2 Query parts.
Scenario 2: 1 Queries, 6.01 Query parts.
Preferences Check
Determines if the preferences on the client need to be updates or the server needs to be updated. If the server needs to be updated then an update query is submitted.
Scenario 1: 20 Queries, 120.2 Query parts.
Scenario 2: 1 Queries, 6.01 Query parts.
Handle Reported Results
Here each result is looked up to see if it was assigned to the person reporting it and to update its values. The workunit record for each result record has to be updated so the transitioner will look at the workunit and decide what to do next. Two indexes have to be updated in the result table and 1 in the workunit table for each result. What is important to point out here is that in scenario 2 we batch all of the selects and updates for results in scenario 1 into a single select and update. The workunit updates are also batched in scenario 2.
Scenario 1: 60 Queries, 342.2 Query parts.
Scenario 2: 3 Queries, 17.11 Query parts.
Assign New Results
Most of the preparation work for this phase is actually done by the feeder. So here we get the latest information about the result, then update the result, then update the workunit.
Scenario 1: 60 Queries, 342.2 Query parts.
Scenario 2: 60 Queries, 342.2 Query parts.
Totals
Now that we have broken down the scheduler into each of its parts and isolated the number and types of queries we can calculate what it would cost the project if each query cost $1. The query parts metric is useful in determining how much wasted database time is spent for each operation. All around scenario 2 costs the project less in time and maintenance on equipment.
Scenario 1 costs a project $11 per result, and scenario 2 costs a project $3.40 per result.
Scenario 2 is 70% more efficient than scenario 1 in the amount of time used to process 20 results.
So be kind to your project(s), let BOINC report the results in batches. The project admin’s will be able to support more people and more machines with the same hardware.
—– Rom
[Edit: Since originally writing this I hunted down a few numbers from jocelyn which is the S@H database server
On average jocelyn is processing 314 queries per second. In the last 5 days jocelyn has processed 144.7 million queries.
]
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
FunctionalAlways active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.